SKT, 매개변수 표준·경량 모델 2종 공개
다른 LLM 대비 고용량 정보처리·비용절감
KT가 자체 개발한 한국적 AI 모델 '믿:음 2.0'
언어·문화적 특성 반영한 한국적인 AI 구현
LGU+, 한발 앞선 LG AI연구원 경쟁력으로
'안티딥보이스' 통신 특화 AI 서비스 상용화


[포인트데일리 손지하 기자] 국내 주요 통신사가 자체 개발한 한국어 특화 인공지능(AI) 모델을 오픈소스로 공개하며 글로벌 AI 시장에서의 경쟁력 확보에 나섰다. SK텔레콤, KT, LG AI연구원이 각각 개발한 대규모 언어모델(LLM)을 무료로 개방함으로써 국내 AI 생태계 활성화와 함께 해외 기업들과의 본격적인 기술 경쟁을 예고하고 있다.
3일 SK텔레콤은 한국어 특화 LLM인 '에이닷 엑스(A.X) 4.0'을 세계적인 오픈소스 커뮤니티 허깅페이스를 통해 공개했다고 발표했다. 같은 날 KT 역시 자체 개발한 '믿:음 2.0' 모델의 오픈소스 공개 계획을 밝혔다. LG AI연구원도 지난 3월 추론 AI 모델 '엑사원 딥'을 오픈소스로 공개한 바 있다.
◇SKT 'A.X 4.0', GPT-4o 대비 33% 높은 토큰 효율=SK텔레콤이 공개한 A.X 4.0은 720억개 매개변수의 표준 모델과 70억개 매개변수의 경량 모델 2종으로 구성됐다. 오픈소스 모델인 Qwen2.5에 방대한 한국어 데이터를 추가 학습시켜 국내 비즈니스 환경에 최적화된 성능을 구현했다.
특히 SK텔레콤이 자체 설계한 토크나이저를 적용한 결과 같은 한국어 문장을 입력했을 때 GPT-4o보다 약 33% 높은 토큰 효율을 기록했다. 대표적인 한국어 능력 평가 벤치마크인 KMMLU에서는 78.3점으로 GPT-4o의 72.5점을 상회했으며 한국어 및 한국 문화 벤치마크인 CLIcK에서도 83.5점을 획득해 GPT-4o의 80.2점보다 우수한 성과를 보였다.
SK텔레콤은 데이터 보안을 고려해 기업 내부 서버에 직접 설치할 수 있는 온프레미스 방식으로도 서비스를 제공할 예정이라고 밝혔다. 김지원 SK텔레콤 AI 모델 랩장은 "국내 비즈니스 환경에 최적화된 모델이 될 수 있도록 지속적인 기술 개발을 추진할 계획"이라고 말했다.

◇KT '믿:음 2.0', 한국적 AI 철학 구현=KT가 선보인 '믿:음 2.0'은 115억 파라미터 규모의 '베이스' 모델과 23억 파라미터 규모의 '미니' 모델 2종으로 구성됐다. KT는 이를 '한국적 AI'라는 철학을 담아 개발했다고 설명했다. KT의 한국적 AI는 한국에 가장 잘 맞는, 한국에 최적화된 AI를 의미한다. 고객국가, 기업, 개인을 가장 잘 이해하며 고객의 AI 전환 선도를 목표로 한다.
믿:음 2.0은 KT와 고려대학교가 공동 개발한 한국어 AI 역량 평가 지표인 'Ko-소버린' 벤치마크에서 유사 규모의 국내 기성 모델과 글로벌 최고 수준의 오픈소스 모델을 능가하는 성과를 기록했다. 또한 KMMLU와 한국어 언어모델 평가 지표인 HAERAE에서도 국내외 주요 오픈소스 모델보다 우수한 성능을 보였다.
KT는 국내 교육용 도서와 문학 작품, 법률 및 특허 문서, 각종 사전 등 다양한 분야에서 한국 특화 데이터를 확보해 학습에 활용했다. 특히 저작권 이슈가 있는 데이터는 모두 제거하고 고품질 데이터만을 선별해 가공했다고 강조했다.
신동훈 KT 젠 AI 랩장은 "믿:음 2.0은 한국의 문화와 언어를 깊이 이해하도록 고도화된 AI 모델"이라며 "국내 사용자들에게 고성능 한국적 AI 모델에 대한 새로운 대안을 제시하는 글로벌 경쟁력의 발판이 될 것"이라고 말했다.

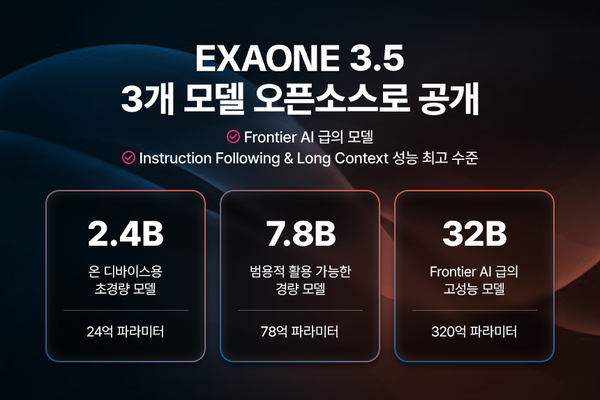
◇LG '엑사원 딥', 추론 AI로 차별화=LG AI연구원은 추론 인공지능 모델 '엑사원 딥'으로 차별화를 꾀했다. 320억개 매개변수의 32B 모델, 경량 모델 7.8B, 온디바이스 모델 2.4B 등 3가지로 구성된 엑사원 딥은 단계적인 사고 과정을 거쳐 논리적인 답을 도출하는 추론 능력을 갖췄다.
특히 32B 모델은 매개변수가 6170억개인 중국 딥시크 R1 모델의 5% 규모임에도 경쟁력 있는 성능을 보였다. 2025학년도 대학수학능력시험 수학 영역에서 94.5점으로 딥시크 R1의 89.9점을 앞섰으며 미국 수학경시대회 AIME에서도 90점으로 딥시크보다 3.3점 높은 성과를 기록했다.
LG AI연구원은 "엑사원 딥은 글로벌 기업들과 경쟁할 수 있는 국내 첫 추론 AI 모델"이라며 "한국 기업이 자체 개발한 추론 AI가 글로벌 시장에서 본격적으로 경쟁력을 입증했다는 점에서 의미가 있다"고 평가했다.
LG유플러스는 통신업에 AI를 접목해 사회적 문제로 급부상한 피싱 범죄 예방에 나섰다. LG유플러스는 AI로 위조된 목소리를 실시간으로 판별하는 '안티딥보이스' 기술을 세계 최초로 상용화했다. 이 기술은 보이스피싱 범죄자들이 자녀나 기업 최고경영자의 목소리를 흉내내는 신종 사기 수법에 대응하기 위해 개발됐다.
안티 딥보이스 기술은 통화 중 보이스피싱 위험이 감지될 때 AI가 상대방의 목소리가 위조됐는지 5초 이내에 판별해 사용자에게 경고한다. 최윤호 AI 에이전트 추진그룹장은 "보이스피싱 대응은 통신 사업자로서의 기본적인 의무"라며 "궁극적으로는 개개인의 감정까지 케어할 수 있는 'AI 안심 에이전트'로 진화하고자 한다"고 말했다.
◇오픈소스 전략으로 생태계 확산 노려=통신 3사가 공통적으로 채택한 오픈소스 전략은 국내 AI 생태계 활성화와 글로벌 경쟁력 확보를 위한 포석으로 분석된다. 기업과 개인, 공공기관 누구나 상업적으로 활용할 수 있도록 제약 없이 개방함으로써 자체 AI 모델의 확산과 파생 서비스 개발을 촉진하겠다는 전략이다.
업계 관계자는 "국내 통신사가 한국어 특화 AI 모델을 공개한 것은 글로벌 AI 시장에서 한국의 기술 주권을 확보하려는 전략적 움직임으로 해석된다"며 "특히 오픈AI나 구글 같은 해외 기업들이 주도하는 AI 시장에서 한국어 처리 능력을 무기로 차별화를 시도하는 것으로 보인다"고 말했다.
한편 SK텔레콤은 이달 중 수학 문제 해결과 코드 개발 능력이 강화된 추론형 모델을 추가로 공개할 예정이며 KT도 마이크로소프트와의 협업 모델을 순차 공개할 계획이다. LG유플러스는 안티딥보이스 기술을 시작으로 통화 전 과정에 걸친 보안 서비스를 확대한다는 방침이다.